library(tidyverse)
library(quanteda)
library(quanteda.textstats)
library(quanteda.extras)
library(cmu.textstat)
library(udpipe)
library(gt)7 Part-of-Speech Tagging and Dependency Parsing
In the previous lab, we worked with keyness and effect sizes, specifically using log-likelihood and log ratio measures.
We are now going to add to our toolkit by using the same measures, but applied to data that has been tagged and parsed. To our processing pipeline, we will be adding udpipe: https://bnosac.github.io/udpipe/en/
7.1 What does udpipe do?
Before we start processing in R, let’s get some sense of what “universal dependency parsing” is and what its output looks like.
7.1.1 Parse a sample sentence online
Go to this webpage: http://lindat.mff.cuni.cz/services/udpipe/.
And paste the following sentence into the text field:
The company offers credit cards, loans and interest-generating accounts.
Under Model, select the english-ewt-ut model.
Then, click the “Process Input” button. You should now see an output. If you choose the “Show Table” tab, you can view the output in a tabular format.
7.1.2 Basic parse structure
There is a column for the token and one for the token’s base form or lemma.
Those are followed by a tag for the general lexical class or “universal part-of-speech” (upos) tag, and a tree-bank specific (xpos) part-of-speech tag.
The xpos tags are Penn Treebank tags, which you can find here: https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html
The part-of-speech tags are followed by a column of integers that refer to the id of the token that is at the head of the dependency structure, which is followed by the dependency relation identifier.
For a list of all dependency abbreviations see here: https://universaldependencies.org/u/dep/index.html.
7.1.3 Visualize the dependency
From the “Output Text” tab, copy the output starting with the sent_id, including the pound sign.
Paste the information into the text field here: https://urd2.let.rug.nl/~kleiweg/conllu/. Then click the “Submit Query” button below the text field. This should generate a visualization of the dependency structure.
7.2 Load the needed packages
7.3 Parsing
7.3.1 Preparing a corpus
When we parse texts using a model like ones available in udpipe or spacy, we need to do very little to prepare the corpus. We could trim extra spaces and returns using str_squish() or remove urls, but generally we want the text to be mostly “as is” so the model can do its job.
7.3.2 Download a model
You only need to run this line of code once. To run it, remove the pound sign, run the line, then add the pound sign after you’ve downloaded the model. Or you can run the next chunk and the model will automatically be downloaded in your working directory.
# udpipe_download_model(language = "english")7.3.3 Annotate a sentence
txt <- "The company offers credit cards, loans and interest-generating accounts."
ud_model <- udpipe_load_model("../models/english-ewt-ud-2.5-191206.udpipe")
annotation <- udpipe(txt, ud_model)Code
annotation[, 8:15] |>
gt() |>
as_raw_html()| token_id | token | lemma | upos | xpos | feats | head_token_id | dep_rel |
|---|---|---|---|---|---|---|---|
7.3.4 Plot the annotation
We can also plot the dependency structure using igraph:
library(igraph)
library(ggraph)First we’ll create a plotting function.
plot_annotation <- function(x, size = 3) {
stopifnot(is.data.frame(x) &&
all(c("sentence_id", "token_id", "head_token_id", "dep_rel",
"token_id", "token", "lemma", "upos", "xpos", "feats") %in% colnames(x)))
x <- x[!is.na(x$head_token_id), ]
x <- x[x$sentence_id %in% min(x$sentence_id), ]
edges <- x[x$head_token_id != 0, c("token_id", "head_token_id", "dep_rel")]
edges <- edges[edges$dep_rel != "punct",]
edges$head_token_id <- ifelse(edges$head_token_id == 0, edges$token_id, edges$head_token_id)
nodes <- x[, c("token_id", "token", "lemma", "upos", "xpos", "feats")]
edges$label <- edges$dep_rel
g <- graph_from_data_frame(edges,
vertices = nodes,
directed = TRUE)
ggraph(g, layout = "linear") +
geom_edge_arc(ggplot2::aes(label = dep_rel, vjust = -0.20), fold = T,linemitre = 2,
arrow = grid::arrow(length = unit(3, 'mm'), ends = "last", type = "closed"),
end_cap = ggraph::label_rect("wordswordswords"),
label_colour = "red", check_overlap = TRUE, label_size = size) +
geom_node_label(ggplot2::aes(label = token), col = "black", size = size, fontface = "bold") +
geom_node_text(ggplot2::aes(label = xpos), nudge_y = -0.35, size = size)
}And plot the annotation:
plot_annotation(annotation, size = 2.5)Warning in geom_node_label(ggplot2::aes(label = token), col = "black", size =
size, : Ignoring unknown parameters: `label.size`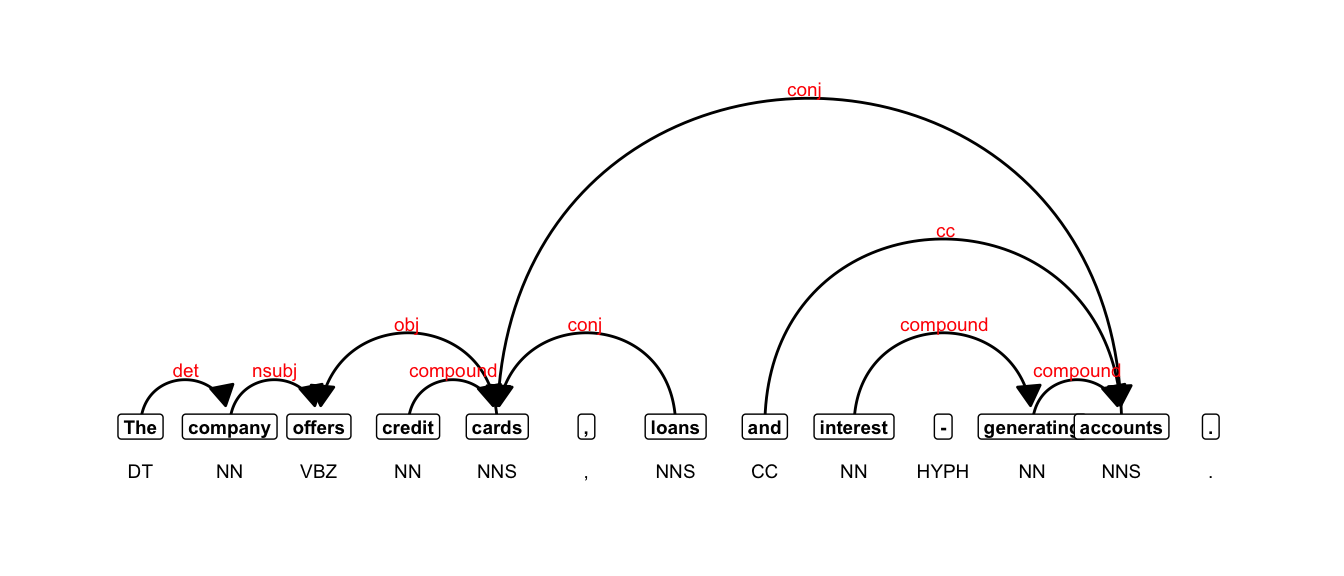
7.4 Annotate a corpus
Parsing text is a computationally intensive process and can take time. So for the purposes of this lab, we’ll create a smaller sub-sample of the the data. By adding a column called text_type which includes information extracted from the file names, we can sample 5 texts from each.
set.seed(123)
sub_corpus <- quanteda.extras::sample_corpus |>
mutate(text_type = str_extract(doc_id, "^[a-z]+")) |>
group_by(text_type) |>
sample_n(5) |>
ungroup() |>
dplyr::select(doc_id, text)7.4.1 Parallel processing
Parallel processing is a method whereby separate parts of an overall complex task are broken up and run simultaneously on multiple CPUs, thereby reducing the amount of time for processing. Part-of-speech tagging and dependency parsing are computationally intensive, so using parallel processing can save valuable time.
The udpipe() function has an argument for assigning cores: parallel.cores = 1L. It’s easy to set up, so feel free to use that option.
A second option requires more preparation, but is even faster. So we’ll walk through how it works. First, we will split the corpus based on available cores.
corpus_split <- split(sub_corpus, seq(1, nrow(sub_corpus), by = 10))For parallel processing in R, we’ll use the package future.apply.
library(future.apply)Next, we set up our parallel session by specifying the number of cores, and creating a simple annotation function.
ncores <- 4L
plan(multisession, workers = ncores)
annotate_splits <- function(corpus_text) {
ud_model <- udpipe_load_model("english-ewt-ud-2.5-191206.udpipe")
x <- data.table::as.data.table(udpipe_annotate(ud_model, x = corpus_text$text,
doc_id = corpus_text$doc_id))
return(x)
}Finally, we annotate using future_lapply. On my machine, this takes roughly 7 seconds.
annotation <- future_lapply(corpus_split, annotate_splits, future.seed = TRUE)As you might guess, the output is a list of data frames, so we’ll combine them using bind_rows().
annotation <- bind_rows(annotation)7.5 Process with quanteda
7.5.1 Format the data for quanteda
If we want to do any further processing in quanteda, we need to make a couple of adjustments to our data frame.
anno_edit <- annotation |>
dplyr::select(doc_id, sentence_id, token_id, token, lemma,
upos, xpos, head_token_id, dep_rel) |>
rename(pos = upos, tag = xpos)
anno_edit <- structure(anno_edit, class = c("spacyr_parsed", "data.frame"))7.5.2 Convert to tokens
sub_tkns <- as.tokens(anno_edit, include_pos = "tag", concatenator = "_")7.5.3 Create a dfm
We will also extract and assign the variable text_type to the tokens object.
doc_categories <- names(sub_tkns) %>%
data.frame(text_type = .) %>%
mutate(text_type = str_extract(text_type, "^[a-z]+"))
docvars(sub_tkns) <- doc_categories
sub_dfm <- dfm(sub_tkns)And check the frequencies:
Code
textstat_frequency(sub_dfm, n = 10) |>
gt()| feature | frequency | rank | docfreq | group |
|---|---|---|---|---|
| ._. | 6452 | 1 | 40 | all |
| ,_, | 5900 | 2 | 40 | all |
| the_dt | 5217 | 3 | 40 | all |
| and_cc | 2596 | 4 | 40 | all |
| of_in | 2513 | 5 | 40 | all |
| a_dt | 2256 | 6 | 40 | all |
| to_to | 1702 | 7 | 40 | all |
| in_in | 1645 | 8 | 40 | all |
| i_prp | 1497 | 9 | 36 | all |
| you_prp | 1202 | 10 | 36 | all |
7.5.4 Filter/select tokens
There are multiple ways to filter/select the tokens we want to count. We could, for example, just filter out all rows in the annotation data frame tagged as PUNCT, if we wanted to exclude punctuation from our counts.
I would, however, advise against altering the original parsed file. We may want to try different options, and we want to avoid having to re-parse our corpus, as that is the most computationally intensive step in the processing pipeline. In fact, if this were part of an actual project, I would advise that you save the parsed data frame as a .csv file using write_csv() for later use.
So we will try an alternative. We use the tokens_select() function to either keep or remove tokens based on regular expressions.
sub_dfm <- sub_tkns |>
tokens_select("^.*[a-zA-Z0-9]+.*_[a-z]", selection = "keep", valuetype = "regex",
case_insensitive = TRUE) |>
dfm()And check the frequencies:
Code
textstat_frequency(sub_dfm, n = 10) |>
gt() |>
as_raw_html()| feature | frequency | rank | docfreq | group |
|---|---|---|---|---|
If we want to compare one text-type (as our target corpus) to another (as our reference corpus), we can easily subset the data.
acad_dfm <- dfm_subset(sub_dfm, text_type == "acad") |>
dfm_trim(min_termfreq = 1)
fic_dfm <- dfm_subset(sub_dfm, text_type == "fic") |>
dfm_trim(min_termfreq = 1)And finally, we can generate a keyness table.
acad_v_fic <- keyness_table(acad_dfm, fic_dfm) |>
separate(col = Token, into = c("Token", "Tag"), sep = "_")From that data, we can filter specific lexical classes, like modal verbs:
Code
acad_v_fic |>
filter(Tag == "md") |>
gt() |>
fmt_number(columns = c('LL', 'LR', 'Per_10.4_Tar', 'Per_10.4_Ref'), decimals = 2) |>
fmt_number(columns = c('DP_Tar', 'DP_Ref'), decimals = 3) |>
fmt_number(columns = c('PV'), decimals = 5) |>
as_raw_html()| Token | Tag | LL | LR | PV | AF_Tar | AF_Ref | Per_10.4_Tar | Per_10.4_Ref | DP_Tar | DP_Ref |
|---|---|---|---|---|---|---|---|---|---|---|
7.5.5 Extract phrases
We can also extract phrases of specific types. To so so, we first use the function as_phrasemachine() to add a new column to our annotation called phrase_tag.
annotation$phrase_tag <- as_phrasemachine(annotation$upos, type = "upos")Next, we can use the function keywords_phrases() to extract phrase-types based on regular expressions. Refer to the documentation for suggested regex patterns: https://cran.r-project.org/web/packages/udpipe/refman/udpipe.html#keywords_phrases.
You can also read examples of use cases: https://bnosac.github.io/udpipe/docs/doc7.html.
First, we’ll subset our data into annotations by text-type.
acad_anno <- annotation |>
filter(str_detect(doc_id, "acad"))
fic_anno <- annotation |>
filter(str_detect(doc_id, "fic"))acad_nps <- keywords_phrases(x = acad_anno$phrase_tag, term = tolower(acad_anno$token),
pattern = "(A|N)*N(P+D*(A|N)*N)*",
is_regex = TRUE, detailed = TRUE)
fic_nps <- keywords_phrases(x = fic_anno$phrase_tag, term = tolower(fic_anno$token),
pattern = "(A|N)*N(P+D*(A|N)*N)*",
is_regex = TRUE, detailed = TRUE)Code
acad_nps |>
head(25) |>
gt() |>
as_raw_html()| keyword | ngram | pattern | start | end |
|---|---|---|---|---|
Note that although the function uses the term keywords, it is NOT executing a hypothesis test of any kind.
7.5.6 Extract only unique phrases
Note that udpipe extracts overlapping constituents of phrase structures. Normally, we would want only unique phrases. To find those we’ll take advantage of the start and end indexes, using the between() function from the data.table package.
That will generate a logical vector, which we can use to filter out only those phrases that don’t overlap with another.
idx <- seq(1:nrow(acad_nps))
is_unique <- lapply(idx, function(i) {
sum(data.table::between(acad_nps$start[i], acad_nps$start, acad_nps$end) &
data.table::between(acad_nps$end[i], acad_nps$start, acad_nps$end)) == 1
}
) |>
unlist()
acad_nps <- acad_nps[is_unique, ]idx <- seq(1:nrow(fic_nps))
is_unique <- lapply(idx, function(i) {
sum(data.table::between(fic_nps$start[i], fic_nps$start, fic_nps$end) &
data.table::between(fic_nps$end[i], fic_nps$start, fic_nps$end)) == 1
}
) |>
unlist()
fic_nps <- fic_nps[is_unique, ]We can also add a rough accounting of the lengths of the noun phrases by summing the spaces and adding 1.
acad_nps <- acad_nps |>
mutate(phrase_length = str_count(keyword, " ") + 1)
fic_nps <- fic_nps |>
mutate(phrase_length = str_count(keyword, " ") + 1)Code
fic_nps |>
head(10) |>
gt() |>
as_raw_html()| keyword | ngram | pattern | start | end | phrase_length |
|---|---|---|---|---|---|
ImportantPause for Lab Set Question
Complete Task 2 in Lab Set 2.