[1] -1.50 -1.25 1.75Sentiment Analysis
Alex Reinhart 
Statistics & Data Science 36-468/668
David Brown
Dept. of English
Fall 2025
Sentiment trajectories
syuzhet can also be used for sentiment trajectories, measuring the development of sentiment sentence-by-sentence through a text
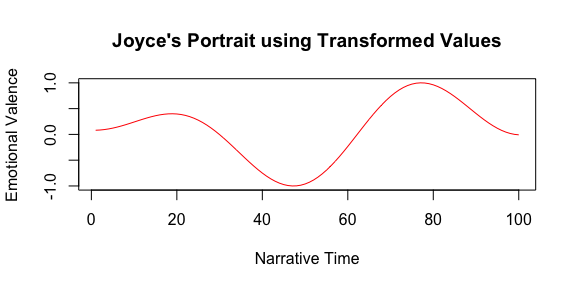
(from syuzhet vignette)
Could this measure narrative arcs, distinguishing tragedies from comedies from dramas?
Narrative arcs
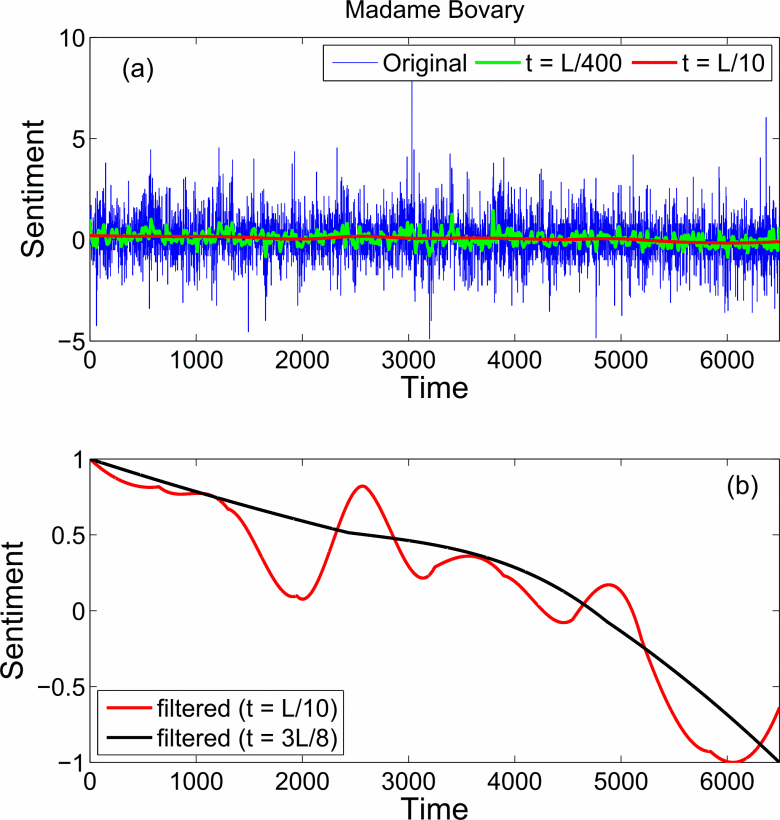
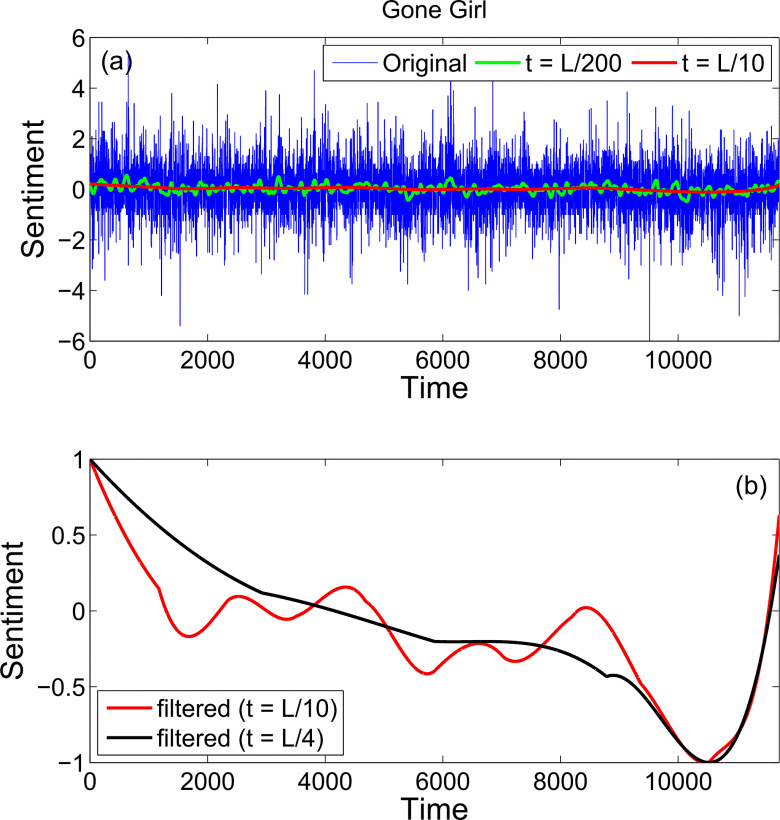
(Gao et al. (2016), figs 1 and 2)