| ID | Category Name | Number of Texts |
|---|---|---|
| A | Press: Reportage | 44 |
| B | Press: Editorial | 27 |
| C | Press: Reviews | 17 |
| D | Religion | 17 |
| E | Skill And Hobbies | 36 |
| F | Popular Lore | 48 |
| G | Belles-Lettres | 75 |
| H | Miscellaneous: Government & House Organs | 30 |
| J | Learned | 80 |
| K | Fiction: General | 29 |
| L | Fiction: Mystery | 24 |
| M | Fiction: Science | 6 |
| N | Fiction: Adventure | 29 |
| P | Fiction: Romance | 29 |
| R | Humor | 9 |
Large Language Models 🎃
How we got here and how that history can help us evaluate what they produce
David Brown 
RSA (Three Rivers)
October 31, 2024
History
Writing is inseparable from technological change
- Technological change is often met with skepticism, if not hostility and fear.

Think of the moral and intellectual training that comes to a student who writes a manuscript with the knowledge that his [sic] errors will stand out on the page as honestly confessed and openly advertised mistakes. (S. Y. G. 1908)
History
Writing is inseparable from technological change
- Technological change is often met with skepticism, if not hostility and fear.

The eraser is an instrument of the devil because it perpetuates a culture of shame about error. It’s a way of lying to the world, which says ‘I didn’t make a mistake. I got it right first time.’ That’s what happens when you can rub it out and replace it. Instead, we need a culture where children are not afraid to make mistakes, they look at their mistakes and they learn from them, where they are continuously reflecting and improving on what they’ve done, not being enthralled to getting the right answer quickly and looking smart. (Espinoza 2015)
History
The concept of a language model has been around for a long time…

1960-1980
Beginnings of NLP
1980-2015
Towards Computation
2015-
Emergence of ML
History
The concept of a language model has been around for a long time…
The beginnings of NLP
The question of multiple meanings (or polysemy)

A memo shared with a small group of researchers who were at the forefront of machine translation after WWII, anticipates the challenges and possibilities of the computer analysis of text. (Weaver 1949)
The beginnings of NLP
The question of multiple meanings (or polysemy)

If one examines the words in a book, one at a time as through an opaque mask with a hole in it on word wide, then it is obviously impossible to determine, one at a time, the meaning of words.
The beginnings of NLP
The question of multiple meanings (or polysemy)
But if one lengthens the slit in the opaque mask, until one can see not only the central word in question, but also say [a] N[umber of] words on either side, then if [that] N[umber] is large enough one can unambiguously decide the meaning of the central word.
The beginnings of NLP
The question of multiple meanings (or polysemy)
The practical question is, what minimum value of N will, at least in a tolerable fraction of cases, lead to the correct choice of meaning for the central word?
The beginnings of NLP
- The “context window” is a fundamental insight that powers the training of LLMs (from word2vec to BERT to ChatGPT).
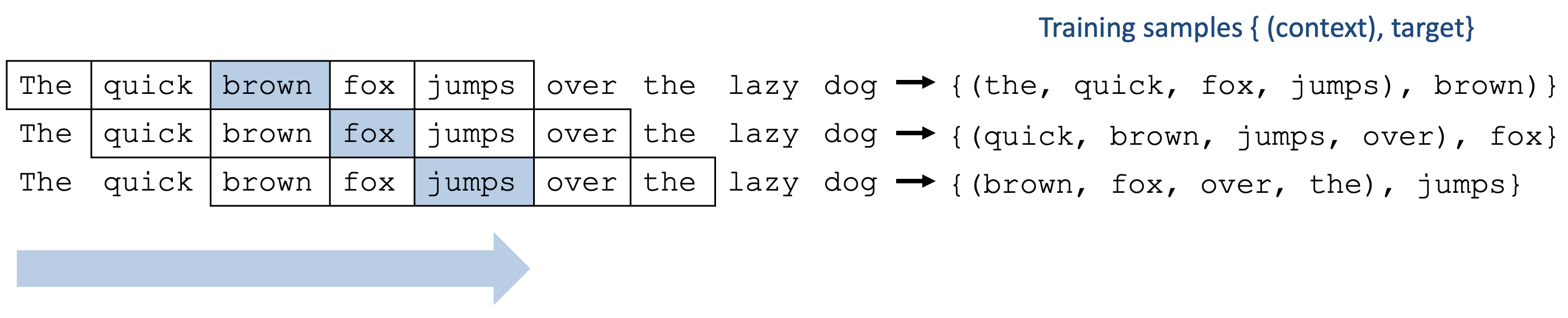
The beginnings of NLP
Context free grammar

The ALPAC Report, which was released in 1966, was highly skeptical of these kinds of approaches.
The beginnings of NLP
Context free grammar

…we do not have useful machine translation. Furthermore, there is no immediate or predictable prospect of useful machine translation.
The beginnings of NLP
Context free grammar

Some of the work must be done on a rather large scale, since small-scale experiments and work with miniature models of language have proved seriously deceptive in the past, and one can come to grips with real problems only above a certain scale of grammar size, dictionary size, and available corpus.
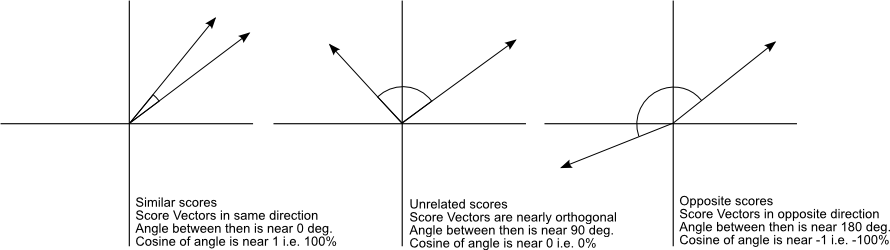
Emergence of ML
Embeddings from a vector model.
- The proximity of words can be assessed using measures like cosine similarity.
\[
cosine~similarity = S_{c}(A, B) := cos(\theta) = \frac{A \cdot B}{||A||~||B||}
\] 
Emergence of ML
- After the introduction of vector representations and, a short time later, the transformer architecture (Vaswani et al. 2017), language models have rapidly evolved. They can be grouped into roughly 3 generations.
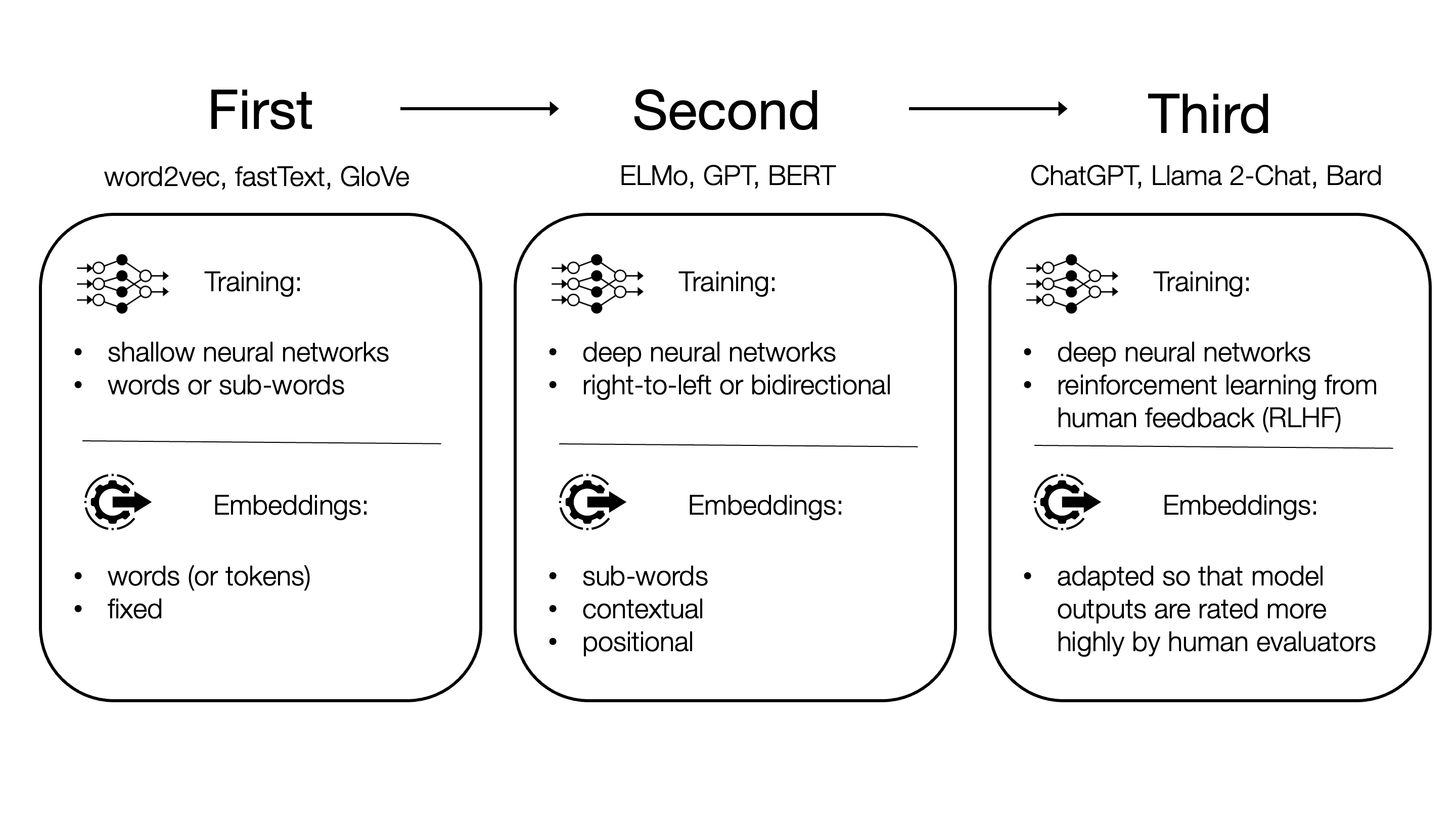
Implications
- The workflow for the creation of a human-AI parallel corpus.

Models were given a 500-word chunk of text and asked to continue writing in the same style, yielding different versions of that second chunk of text.
Implications
- It turns out, machine-authored prose and human-authored prose have some important differences. (Herbold et al. 2023; Reinhart et al. 2024)
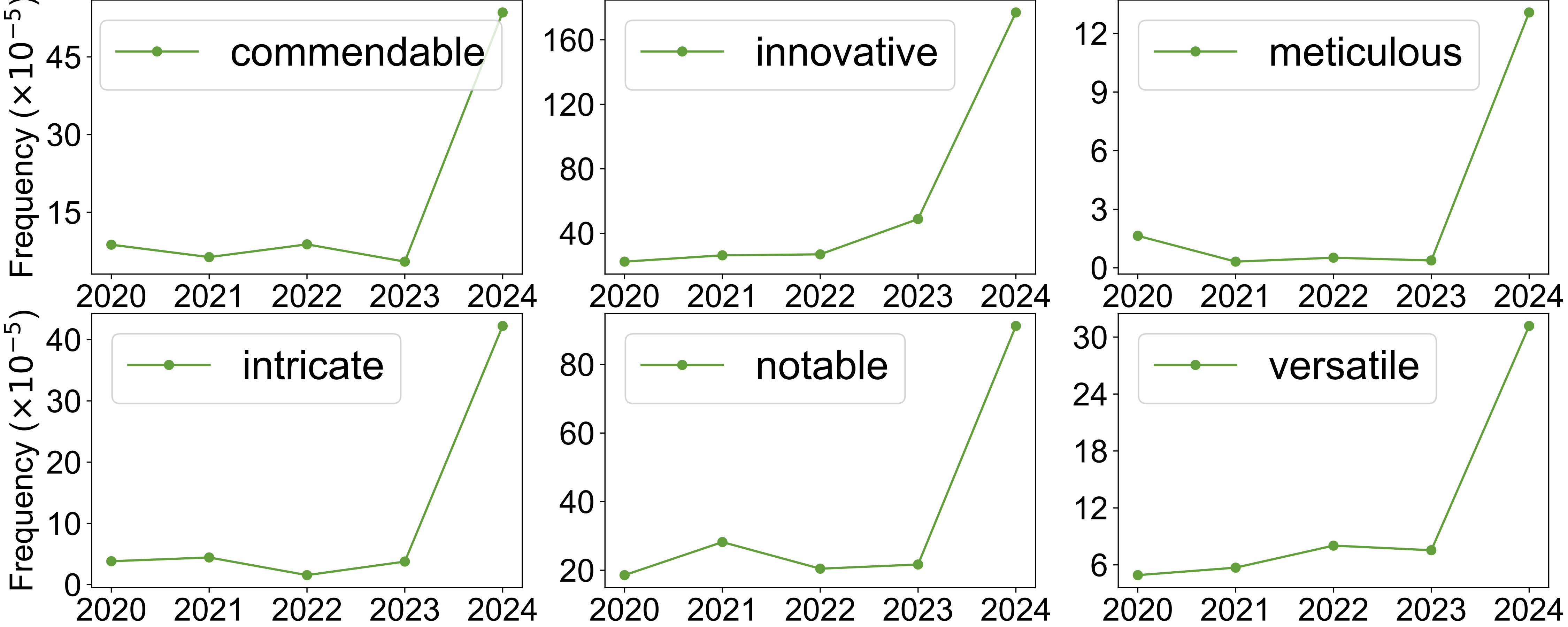
- There are, for example, clear patterns in the relative frequencies of lemmatized words.
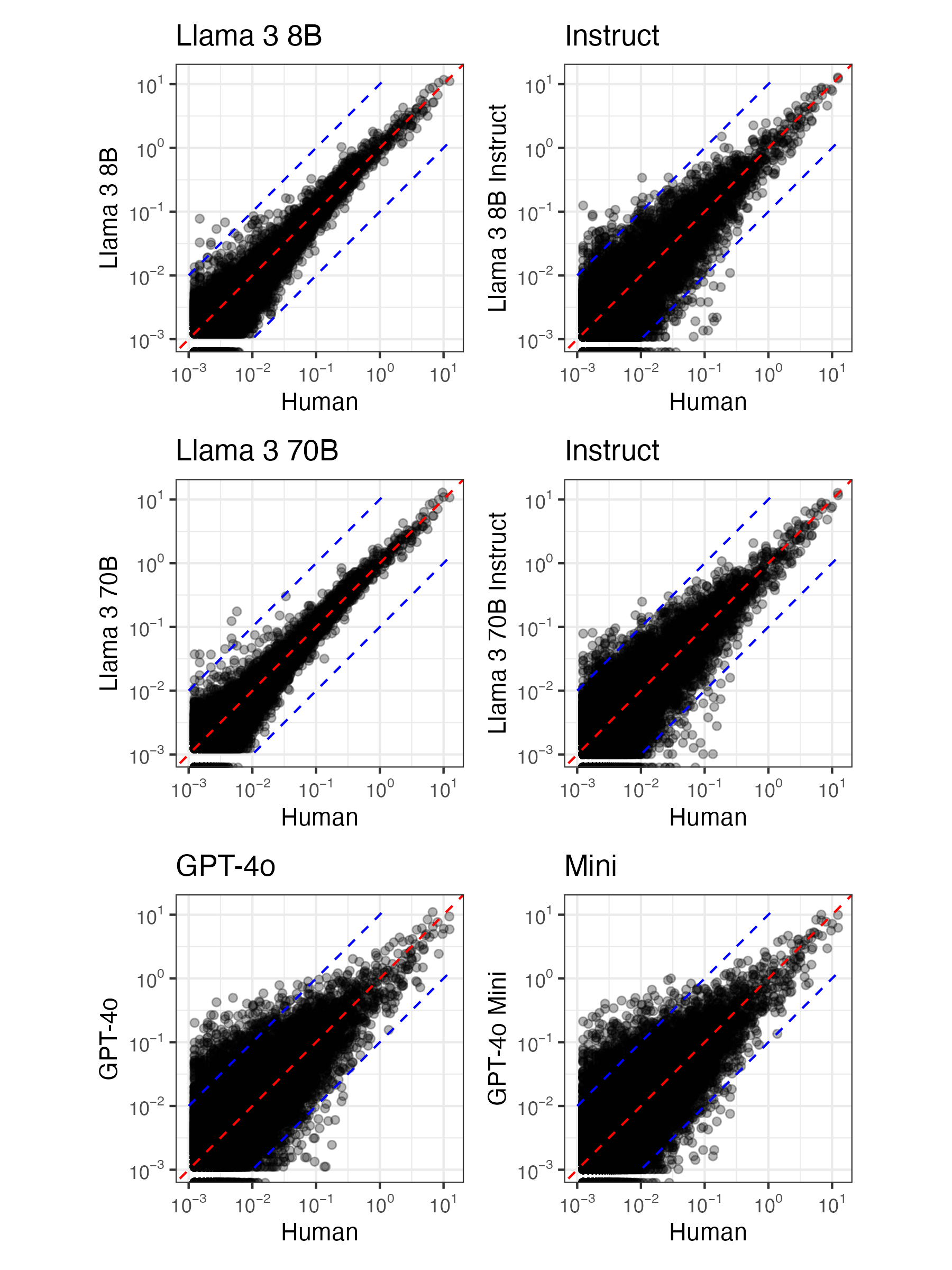
Rates of word use by different LLMs (per 1,000 words) compared to the human use of each word in chunk 2 (log scale). Includes all words used more than once per million words in chunk 2. Words are lemmatized to group together inflected forms. Dashed blue lines indicate the range between 10× more and 10× less than human use. Note that the instruction-tuned models show more variation from the diagonal, indicating more deviation in vocabulary use relative to humans.
Implications
- The over-represented words align with those noted in a study of peer reviews for a large machine learning conference. They measured an uptick of suspiciously positive words after the release of ChatGPT. (Liang et al. 2024)
Implications
- Carrying our principal component analysis (PCA) on the chunk 2 of the human writing, yields a first principal component (PC1) that strongly resembles Biber’s Demension 1 (Involved vs. Informational Production).
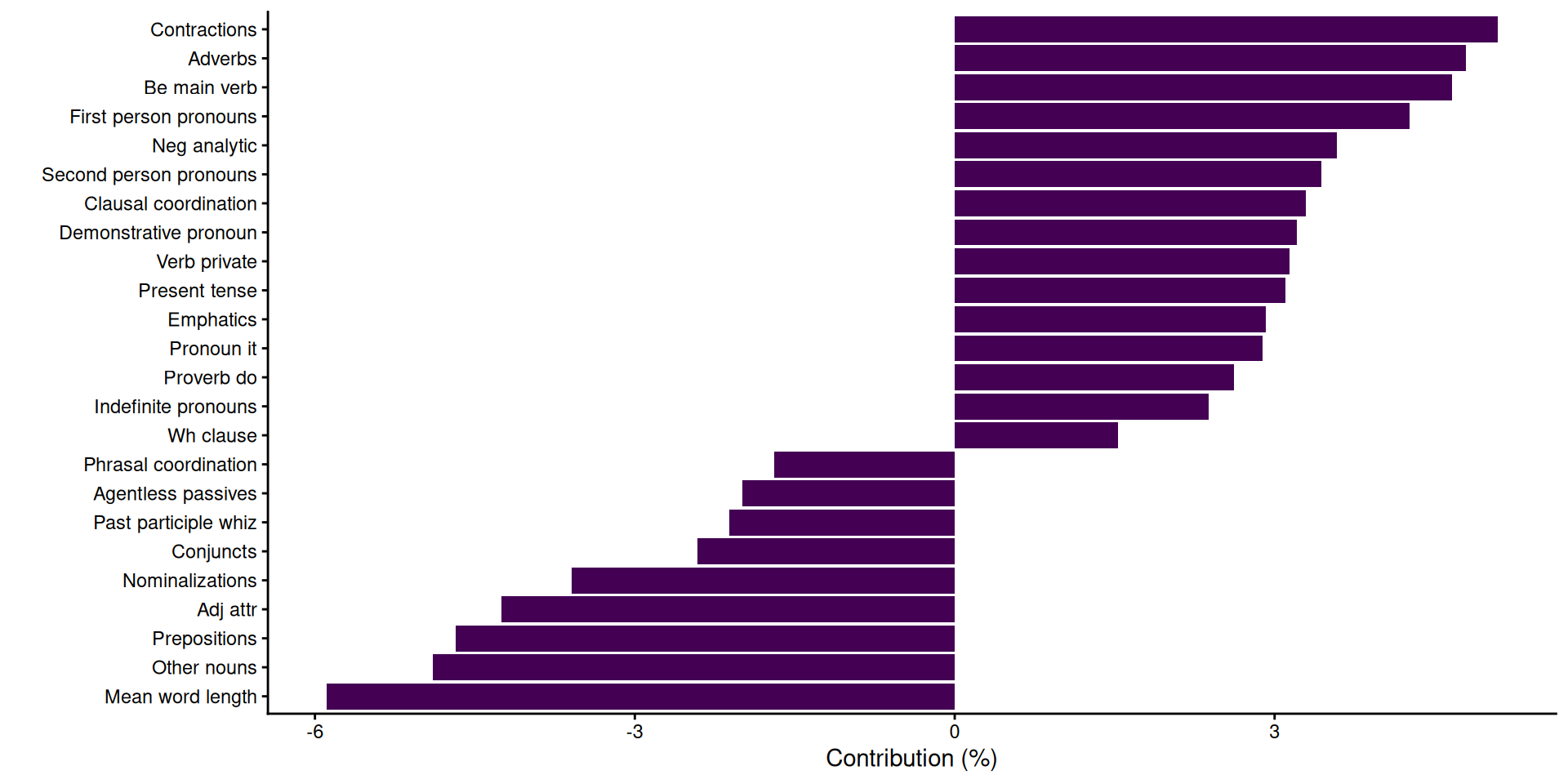
Contributions of features to PC1 (based on human chunk 2).
Implications

Projection of human chunk 2 writing onto the first principal component, based on the 67 Biber features.
Implications

Projection of human chunk 2 writing and Llama Base onto the first principal component.
Implications

Projection of human chunk 2 writing and Llama Instruct onto the first principal component.
Implications

Projection of human chunk 2 writing and GPT 4o onto the first principal component.
Implications
- We found similar patterns when we examined the differences between student writing and LLM-generated writing using examples for an introductory data science assignment. (Markey et al. 2024)

Projection of student, published, and ChatGPT-generated writing onto the first two linear discriminants, based on the 67 Biber features.
Implications
